A Journey into AI image processing: MiDaS for depth estimation

In the past few month I got very enthusiastic about AI image generation. craiyon.com and dream.ai were a source of many hours of entertainment trying to get the model to produce images I find interesting, funny or useful as inspiration.
But all those amazing tools run on servers hosted by other people and given that we are in kind of a wild west gold rush period of AI generation those services might vanish every other day. The reasons might be financial issues, merging, updating (I really didn't like the results of craiyon's v2 model at first), personal or legal reasons (I wonder how long it will take until we have decided what copyright has to say about those creations).
Setting up stable diffusion on my own machine or training such models on my own seemed a bit intimidating und looking for something lighter (from a complete novice's point of view) I got the idea to try depth estimation of existing images.
The very first search result pointed me to MiDaS.
And it initially checked some of my boxes:
- It says that it actually solves my self-imposed task.
- It is kind of recent (January 2023) but also has some iterations that brought it to version 3.1.
- And finally, it comes with a Dockerfile that should make it trivial to set up using Docker.
So here I go. Following the README instructions I build the Docker image:
docker build -t midas .
First setback: The Dockerfile is based on the nvidia/cuda:10.2-cudnn7-runtime-ubuntu18.04 image (Ubuntu 18 is quite old, isn't it?) and the very first apt installation attempt triggers an error:
The following signatures couldn't be verified because the public key is not available: NO_PUBKEY A4B469963BF863CC
Some research pointed me to the fix that made the image build successfully:
[...]
apt-key del 7fa2af80 \
&& apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/3bf863cc.pub \
&& apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub \
[...]
Let's move on and get MiDaS to do some work. I download the medium-sized model "dpt_swin2_large_384" (800MB) into the weights/ directory, place some images into the input/ folder and follow the run instructions:
docker run --rm --gpus all -v $PWD/input:/opt/MiDaS/input -v $PWD/output:/opt/MiDaS/output -v $PWD/weights:/opt/MiDaS/weights midas
Unfortunatelly instead of nice depth maps I get:
docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].
Turned out I neither had the NVidia container runtime installed nor CUDA. Though one year ago when it was time for a new laptop I consciously chose to buy one with a dedicated GPU because "this AI stuff will be the future and sure it will require a good GPU for computation", but until now I didn't get to actually use this piece of hardware.
So on Archlinux I had to install the following packages:
- cuda-12.1.0-1
- libnvidia-container-1.12.0-1
- libnvidia-container-tools-1.12.0-1
- nvidia-container-toolkit-1.12.0-2
And as was to be expected I was greeted with the next stage of error messages instead of some greyscale images:
NVIDIA GeForce RTX 3060 Laptop GPU with CUDA capability sm_86 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_70.
The NVIDIA GeForce RTX 3060 is not supported by PyTorch? How can this be? The catch here is that the Dockerfile is based on an Ubuntu 18 distribution that in turn brings along Python 3.6 that in turn doesn't run the lattest version of PyTorch which means that it can only use CUDA on older GPUs.
Wondering how it comes that a project implementing a technology described in a paper from 2022 bases its Docker infrastructure on an operating system from 2018 I was astonished to find out that this project actually started in 2019 and added a Dockerfile in 2020. That makes sense than.
At this point my options were to base the image onto a newer version of the nvidia/cuda image - which from my experience would trigger a waterfall of changes down the Dockerfile - or roll without GPU support - in the end my CPU should be capable to process at least some small images.
I decided to go without GPU support for now.
Segmentation fault (core dumped)
That's getting annoying. To cut this episode short and don't bother you with my attempts to debug this Python script: The culprit was a picture containing an Umlaut character ("ü") in its filename within the images I had randomly chosen from my collection. Somehow that caused the script to segfault.
Rename. Run. And finally the first result:
docker run --rm -v $PWD/input:/opt/MiDaS/input -v $PWD/output:/opt/MiDaS/output -v $PWD/weights:/opt/MiDaS/weights midas

Here we have it. The model got a 2D flat image as input and was able to decide which pixel in this image represents something that was closer to the camera and which ones are further away. Something we as humans are quite capable of. But computer vision until recently had to rely on the same techniques that a person uses: But instead of two eyes it needed two images - see photogrammetry.
The result from MiDaS above is not very sharp but we can clearly see and distinguish people and objects. Though it lacks some finer granularity at some objects there are no real errors in the estimation. In the worst case objects are placed on the same depth plane that are actually a bit in front or back. Beforehand I didn't know what to expect so judging if this was a good result or not was beyond me. Still I was happy to have gotten it to work in the end. (Will an AI model ever be "intelligent" enough to decide from whom it doesn't want to be used?)
The thing is slow. On my CPU it takes around 5 seconds for an image with 500px on the shorter side. If I let MiDaS do the shrinking and upscaling afterwards of a normal sized image it takes around 30 seconds. I hope that one day I will be able to see how much faster the GPU will do the processing.
But now it's time for experimentation. I downloaded a smaller ("dpt_swin2_tiny_256.pt" - 172MB) and the largest ("dpt_beit_large_512.pt" - 1.6GB) model, collected a new batch of different images I deemed should be interesting tests for this kind of processing and let it calculate. Here I want to present to you some of the more interesting finds.









Let's see how the model handles paintings.


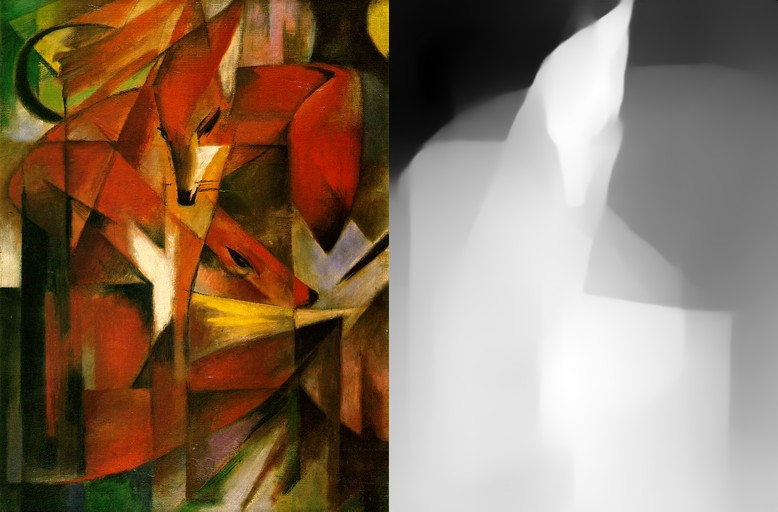

Even the results for the abstract painting by Franz Marc and the painting by Maja Wrońska with a lot of white space are looking quite reasonable.
All in all I'm very happy and impressed with the results even though I had hoped that the technical setup to achieve this was more straight forward.
A short last note: The image processing exports next to the PNG result file a monochrome PFM image file. This is a very simple encoding that supports floating-point number color precision. So you can have an even higher depth resolution when you are using this file. You can read more about the file format at https://www.pauldebevec.com/Research/HDR/PFM/. Gimp and GThumb were not able to display those images out of the box - but than how should they on an 24bit RGB display?